One of the most frequent tasks at Jaskov Consult ApS is technical SEO analysis, where we help our customers with website optimization by finding points of interest.
Our preferred tool for executing a technical SEO analysis is the so-called Screaming Frog SEO Spider Tool, and during this guide we will do our utmost to help you gain the fundamental knowledge of the tool, so you’ll be able to perform the same kind of technical SEO analysis as we do in our daily work.
In this guide, we have chosen our own website as the example site, where we will describe the workflow behind an analysis.
The Screaming Frog SEO Spider tool is extremely useful as it, among other things, scans the selected website for missing Meta Descriptions, improper Page Titles, Duplicate Content and other possibilities for further optimization. This is very important when it comes to creating the best possible User Experience, which could be said to be one of the most important tasks in the SEO world.
Step 1: Open the Screaming Frog SEO Spider program
The first thing you have to do is download the tool from https://www.screamingfrog.co.uk/seo-spider/. Notice that you can choose between a free version or pay for a license. We recommend paying for a license as it gives you access to the full functionality of the program. However, the free version should be sufficient if you are just curious and want to gain an insight into the tool’s capabilities. After a successful installation, you will be met by the following interface:
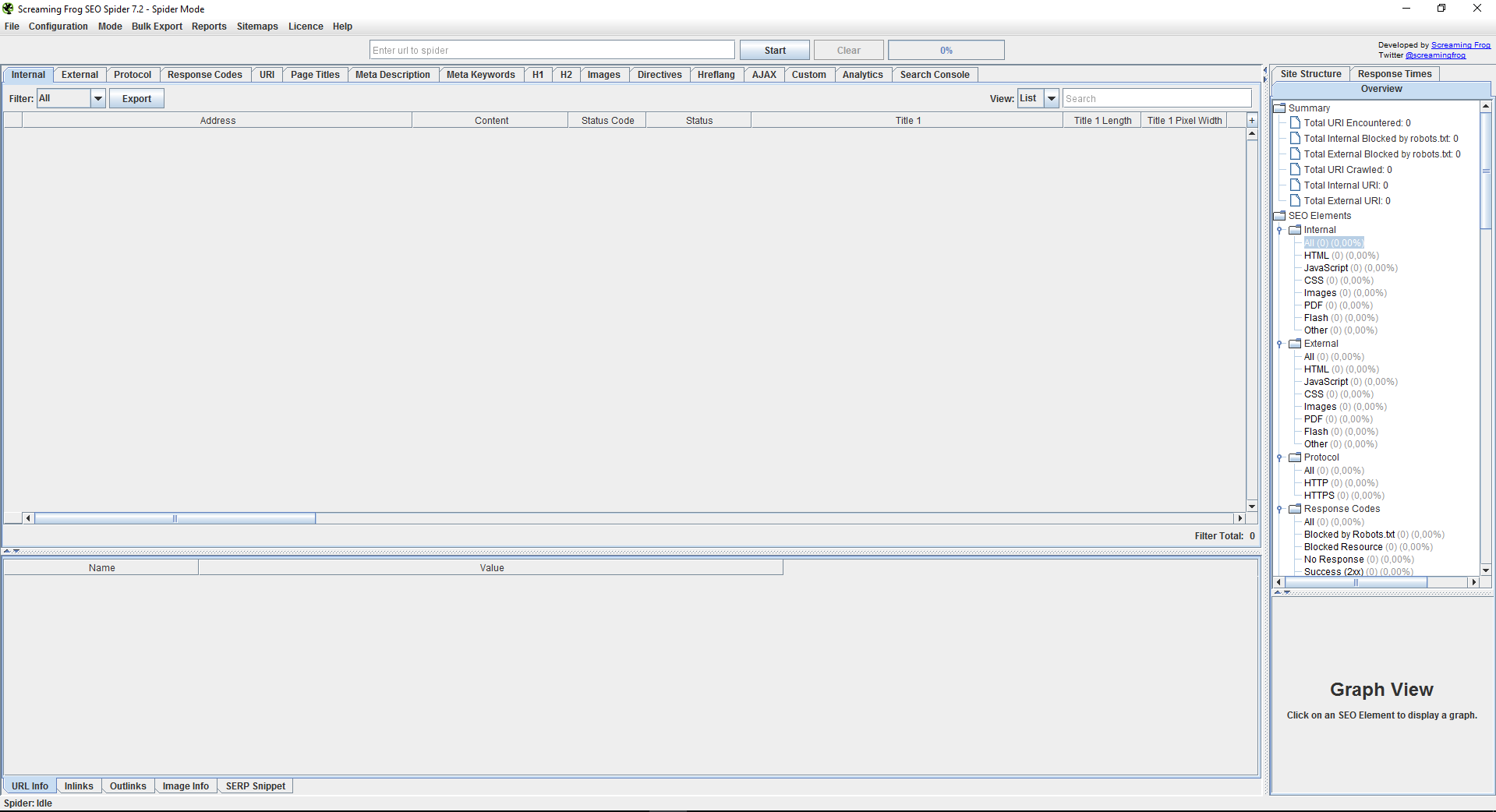
At first glance, the many different tabs can be a bit overwhelming. Fear not, as you quickly will learn to navigate and realize just how well the design works. The many different tabs give you the opportunity for gaining access to a lot of detailed information, which will be explained later in this guide.
Step 2: Enter the URL you want to scan:

In the uppermost text-area, you can specify the website you want to perform a technical SEO analysis on, starting out with a crawl. We recommend putting in the whole URL as in: https://www.example.com/, to avoid any errors.
Another tip is the possibility of specifying which subfolders you want the tool to crawl by defining it in the URL, as in: https://www.example.com/blog/.
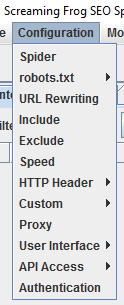
In the ”Configuration” tab, you are also able to select a plethora of different crawl options, which can either expand or restrict your crawl.
After starting your first crawl, you might encounter the following message:
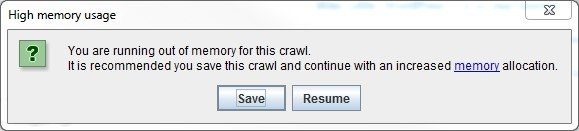
Picture taken from Screaming Frogs own website: https://www.screamingfrog.co.uk/wp-content/uploads/2011/04/high-memory-use.jpg
Which means that the tool is close to using the accessible RAM, which was appointed to the program during installation. The default settings for SEO Spider allocates 512 MB of RAM, which usually is not enough when crawling complex websites.
To increase the amount of RAM that the tool can use you will need to navigate to the folder where the tool is installed. If you did not specify a custom path for Screaming Frog SEO Spider, it can be found in the file path:
C:\Program Files (x86)\Screaming Frog SEO Spider
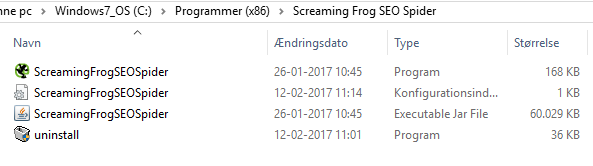
After finding the file path you need to open the file ”ScreamingFrogSEoSpider.l4j” using Notepad or a similar tool, which allows you to edit the file’s content.
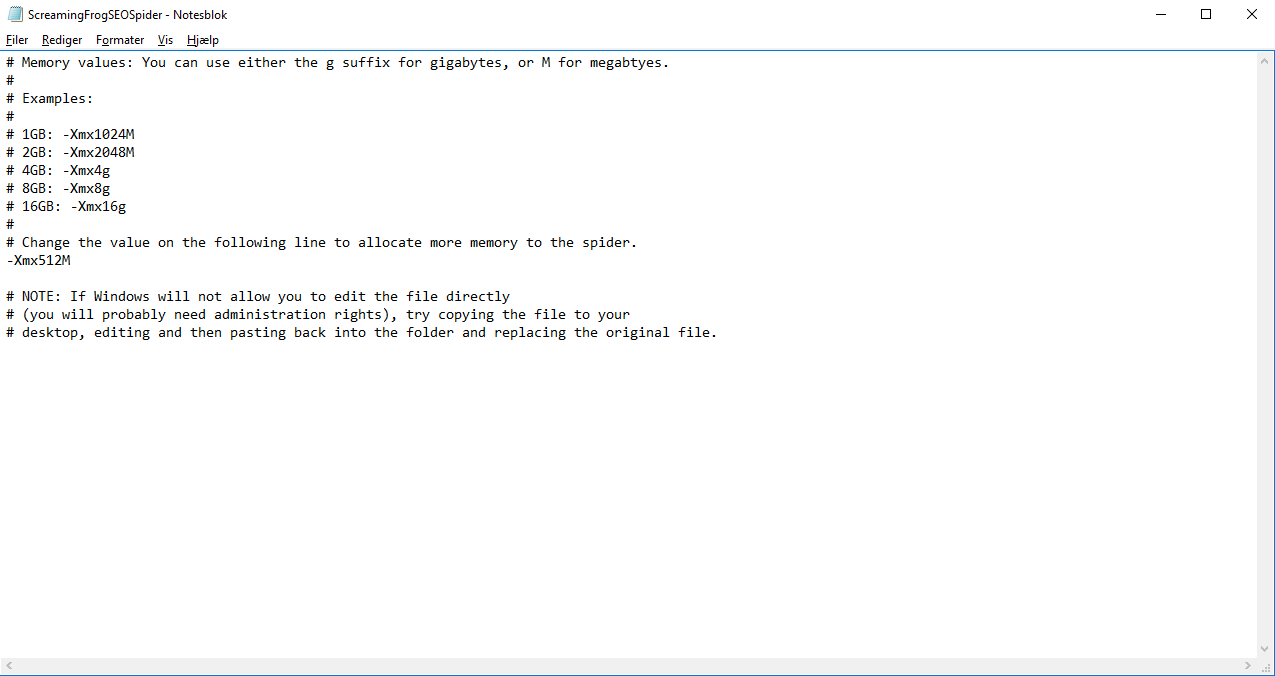
As the picture shows the line of code we’re interested in is named as ”-Xmx512M”, which allocates RAM to the Screaming Frog tool.
We recommend that you allocate as much RAM as your computer allows. If you do not know how much RAM your computer has, it can quickly be found by opening the Windows-menu, right clicking on “This Computer” and choosing “Properties”
Please notice that you should only change the number value in the .l4j file and not the surrounding text. As an example, you should write the following when allocating 6000 MB (6 GB) of RAM:
![]()
After performing the increase, the file must be saved as .ini (not .l4j) to re-initialize the tool’s RAM allocation.
If you use an operating system from Apple or Linux, we refer to Screaming Frog’s own guide.
After a successful allocation of more RAM, you should not encounter any problems while crawling your chosen website.
Step 3: Gain an overview of the data
Once the tool has completed the crawl, you are ready to begin the technical SEO analysis. A lot of information will appear as the example scan shows:
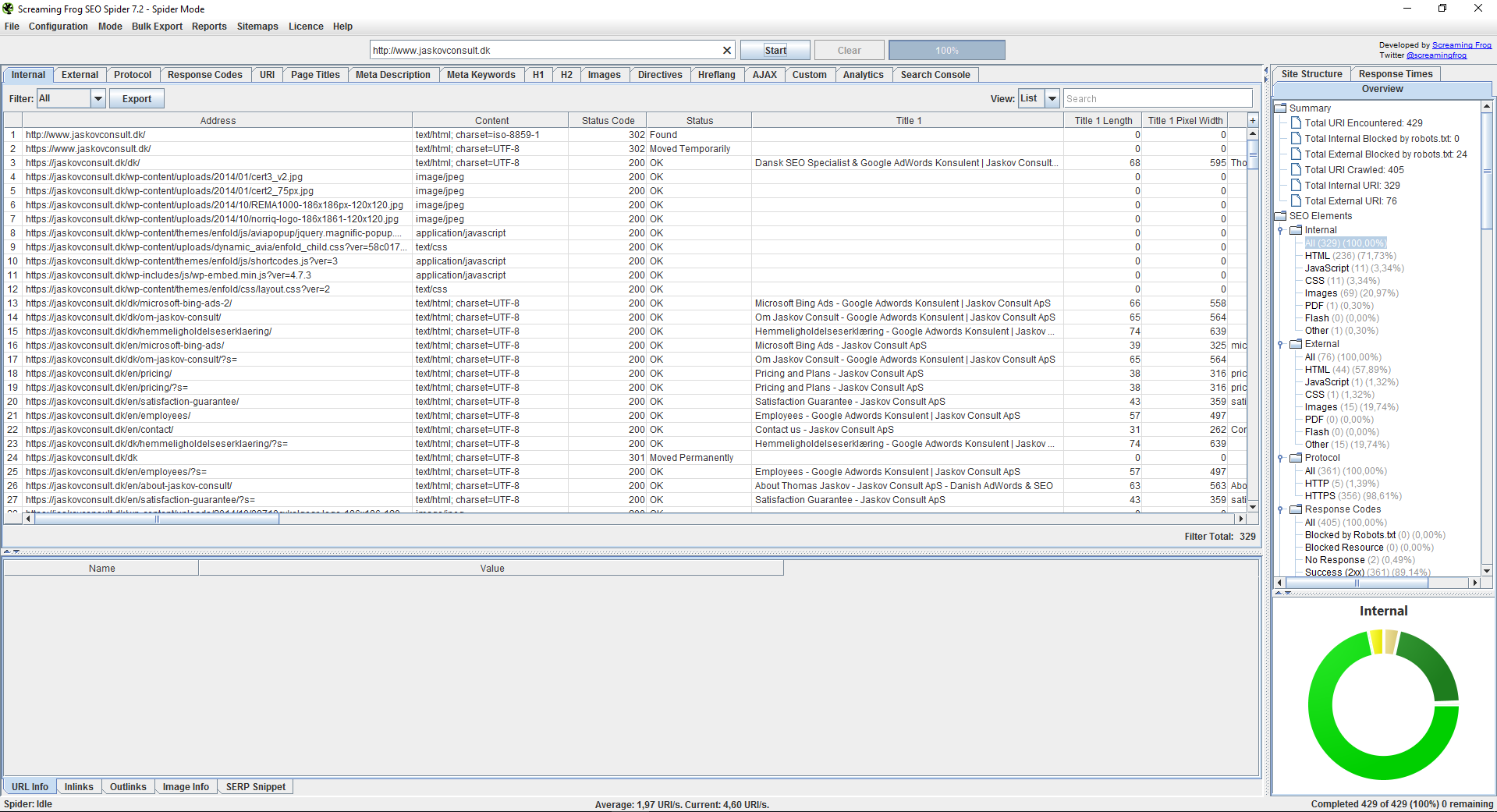
To gain an overview we recommend starting in the right column as the tool gives you a summary of all the ”errors” it found while crawling.
If you wish to investigate a specific group of errors it can be done by clicking on the corresponding folder in the “Summary”-tree.
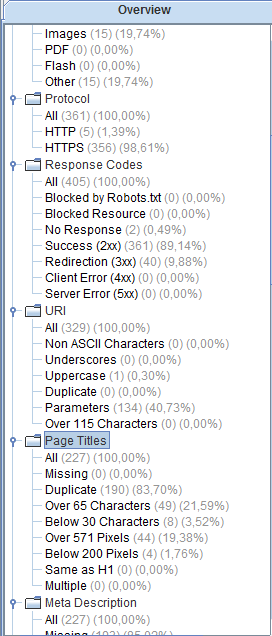
However, you are also able to navigate between the different tabs by clicking on them in the top-menu, if you find that easier. After navigating to a tab of interest, one can filter the results to help with the understanding.
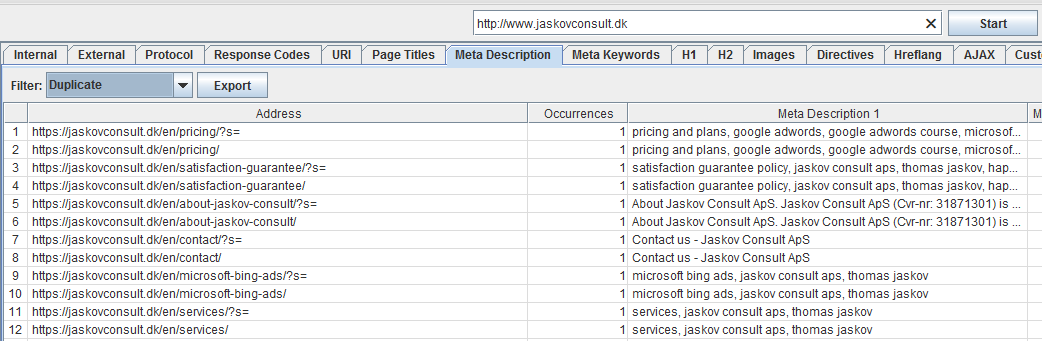
Each tab-category is split up into filters, which tell different things about the URLs containing errors.
The Internal-category is one of the most important categories, as this is where all data is aggregated except from the ”External” and ”Custom” tab. This is done to allow for an easier export into an Excel sheet or similar workbench.
You can export your crawl by selecting the “Export”-button in the category you wish to export data from. If you are interested in exporting all the data, you must go to the “Internal”-tab and choose the “All”-filter and then choose “Export”.
Below this text, you will find a short description of each of the sub-tabs that are contained in the Internal-category. Depending on the complexity/size of a website, the crawl and subsequent technical SEO analysis consist of a mixture of the categories below:
- Address: The URL, which contains an error.
- Content: Which type of content the URL contains. Usually text/html, image/file type, application/file type.
- Status Code: The HTTP response code from the server.
- Status: The HTTP response from the header.
- Title 1: The title of the page.
- Title 1 Length: The length of the title measured in the number of characters or symbols.
- Title 1 Pixel Width: The length of the title measured by the width of the characters in pixels.
- Meta Description 1: The Meta Description for the corresponding URL.
- Meta Description Length 1: The length of the Meta Description measured in the number of characters or symbols.
- Meta Description Pixel Width: The length of the Meta Description measured by the width of the characters in pixels.
- Meta Keyword 1: The Meta Keywords contained in the tag.
- Meta Keywords Length: The length of the keywords measured in the number of characters or symbols.
- H1-1: The first H1 on the corresponding URL.
- H1-1 Length: The length of the H1 measured in the number of characters or symbols.
- H2-1: The first H2 on the corresponding URL.
- H2-1 Length: The length of H2 measured in the number of characters or symbols
- Meta Data 1: Data from the Meta Robots tag such as noindex, nofollow etc.
- Meta Refresh 1: Data from the Meta Refresh tag.
- Canonical: Shows data from the canonical link.
- Size: Shows the URL size measured in bytes.
- Word Count: All words within the <body> tag. The tool defines a word as text separated by a space
- Text Ratio: Amount of words within the <body> tag divided by the total amount of characters on the site.
- Level: The level of the page in reference to the website’s home page. The more clicks it takes to get to the URL the higher the level.
- Inlinks: Amount of internal links which points at the URL
- Internal outlinks: The amount of links from the URL pointing to another URL on the same domain.
- External outlinks: The amount of external links (links pointing to an URL on another domain).
- Hash: A way of checking if there is duplicate content on the website. If two hash-values match, duplicate content is present.
- Response Time: How long it takes for the page to load measured in seconds.
- Last-Modified: A way of telling how long it has been since the page was updated, if the server provides this information.
Every other tab contains a mix of the above sub-tabs, where different filters can be used to gain relevant information.
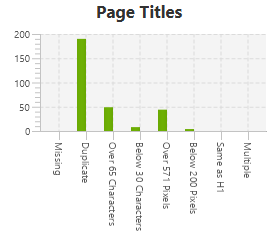
In the bottom right corner there is a graph showing which graphically illustrates the data you have chosen. This can be a very useful tool to make sense of the data, which can be quite overwhelming right after crawling.
Step 4: Start your analysis
Once you have a good idea of the information provided, and have chosen the data of interest that are relevant for your crawled website the actual technical SEO analysis can begin.
By using the tool’s information, you can start fixing the errors or attempt to gain a better understanding of how your website works under the hood to correlate it to the design. An example is that “Multiple H1” is not necessarily a bad thing on a website, which proves that one must spend a bit of time analyzing the data set in relation to the architecture and design of the website.
Of course, the Screaming Frog SEO Spider tool contains several other advanced analysis tools, which one can use after becoming comfortable with the fundamentals. However, this guide’s goal has been to help you complete your first crawl of a website with a walkthrough of the most common properties, which can help you optimize a website of your choice.
We hope that you have gained some knowledge reading this guide and that you now feel prepared for your first technical SEO analysis of a website using the Screaming Frog SEO Spider tool. After performing your first analysis, you might be interested in gathering your findings into a technical SEO report, which we have also written a guide on.